

- La CRL (Certificate Revocation List) liste les certificats révoqués avant expiration pour sécuriser les connexions TLS.
- Les points de distribution (CDP) doivent être accessibles et redondants pour éviter les erreurs de révocation.
- Une CRL périmée ou inaccessible provoque des refus de connexion TLS et des interruptions de service.
- Le cache CRL améliore la performance mais peut retarder la prise en compte des mises à jour.
- OCSP et OCSP stapling complètent la CRL en offrant une vérification en temps réel plus réactive.
- La supervision régulière des dates thisUpdate et nextUpdate est essentielle pour garantir la fiabilité de la CRL.
Quand une application refuse une connexion TLS et vous renvoie une erreur de révocation, ce n’est pas « un navigateur capricieux ». C’est souvent un problème de tuyauterie entre votre autorité de certification, la publication d’une liste, et la façon dont les clients valident un certificat. Et là, on perd vite du temps. Qui publie quoi ? À quel rythme ? Et qui casse en premier quand l’adresse de distribution ne répond plus ? On va poser les définitions, puis descendre dans le concret : champs d’une CRL, points de distribution, cache, OCSP, et dépannage.
CRL : définition (et pourquoi l’acronyme peut désigner plusieurs choses)
On recadre tout de suite ce que « CRL » veut dire dans 90 % des cas en entreprise, puis on donne des repères simples pour reconnaître si vous êtes bien dans un sujet certificats.
La CRL en cybersécurité : la liste de révocation de certificats
Dans le contexte sécurité, CRL signifie « Certificate Revocation List », en français « liste de révocation de certificats ». C’est un fichier publié par une autorité de certification (CA) qui contient la liste des certificats X.509 déclarés invalides avant leur date d’expiration. Dit autrement : c’est la mémoire officielle des certificats que la CA ne veut plus voir acceptés.
Vous croisez ce sujet dès qu’on parle de SSL et TLS, donc typiquement HTTPS sur un site web, un proxy d’entreprise, un réseau privé virtuel, ou une authentification interne basée sur certificats. Le principe reste simple : au moment où le client valide la chaîne de certification (certificat serveur, intermédiaires, racine), il peut aussi vérifier si le certificat a été révoqué.
Concrètement, la CRL sert à répondre à une question binaire : ce numéro de série est-il révoqué ? Si oui, même si le certificat « n’a pas expiré », il doit être rejeté (selon les règles du client et sa politique de validation). C’est précisément ce point qui explique des pannes soudaines alors que « tout avait l’air valide ».
D’autres sens possibles de « CRL » : comment reconnaître le bon contexte
Oui, « CRL » peut vouloir dire autre chose selon les métiers. On voit parfois passer l’acronyme en finance ou en logistique avec des significations internes, et ça crée des quiproquos bêtes. En réunion, deux personnes peuvent parler de « CRL » sans jamais parler du même objet.
Pour reconnaître que vous êtes bien sur le terrain PKI (infrastructure à clé publique), cherchez des indices concrets : certificats X.509, CA, chaîne de certification, navigateur, serveur web, Windows Server, Active Directory Certificate Services (AD CS), OpenSSL, ou encore des mentions comme CDP (CRL Distribution Points). Si vous voyez apparaître des messages du type « CRL expired » ou « unable to get certificate CRL », vous êtes clairement dans le bon sujet.
Posez-vous deux questions rapides. Vous êtes côté informatique ou sécurité ? Et surtout : « Qui a prononcé “CRL” ? » Un administrateur système parlera souvent d’URL, de cache et de dates d’expiration de liste. Un contrôleur de gestion, lui, aura d’autres repères et d’autres urgences.
À quoi sert la liste de révocation dans une PKI (certificats SSL/TLS)
On parle ici du rôle métier : réduire le risque quand quelque chose ne va plus avec un certificat ou sa clé privée. La CRL n’est pas un détail administratif, c’est un mécanisme de contrôle qui peut bloquer un service en production.
Révocation vs expiration : ce que ça change pour vos services
Un certificat expire à une date connue. Ça se gère avec un planning, des rappels et, de plus en plus, de l’automatisation. Une révocation arrive souvent après un événement non planifié : clé privée compromise, erreur d’émission (mauvais nom DNS dans le certificat), changement d’entité légale, ou perte d’un équipement contenant la clé.
Côté service TLS, la différence est nette. Un certificat expiré provoque une panne prévisible si vous n’avez pas renouvelé à temps. Un certificat révoqué peut provoquer une panne brutale si les clients vérifient strictement le statut de révocation, parfois sans que l’équipe applicative ait changé quoi que ce soit.
Et c’est là que les arbitrages commencent. Dans votre situation, qui décide du niveau d’exigence ? Le RSSI impose un contrôle dur, ou l’équipe produit privilégie la continuité ? Les deux positions se défendent selon que vous sécurisez un réseau privé virtuel interne sensible ou une simple page vitrine.
Mini-scénarios : côté navigateur, côté serveur, côté SI interne
Côté navigateur public, beaucoup d’environnements ont historiquement toléré certains échecs de vérification pour éviter des pannes massives sur Internet. Résultat possible : statut « revocation status unknown », mais page quand même accessible. C’est confortable pour l’utilisateur, mais moins satisfaisant si votre modèle de menace inclut le vol de clé.
Côté serveur applicatif (un client d’interface de programmation vers une autre interface), on voit souvent des bibliothèques qui font mieux le travail et échouent plus franchement. Si elles tentent de télécharger la CRL via l’URL indiquée dans les CDP et que ça ne marche pas (proxy bloquant, résolution de noms interne cassée), vous obtenez un refus TLS. Dans la pratique, ce sont souvent quelques flux critiques qui tombent en premier.
En interne SI (poste Windows et AD CS par exemple), c’est encore plus sensible car la validation s’appuie sur des mécanismes système et du cache CRL. Une CRL inaccessible ou périmée peut casser l’ouverture d’une session Wi-Fi 802.1X, l’accès à un portail intranet mutualisé, ou certaines signatures S/MIME. Et comme l’impact est diffus, le diagnostic peut traîner.
Le fonctionnement concret : contenu, format et cycle de vie d’une CRL
On passe à la plomberie : qui publie la liste, sous quelle forme, et comment les clients s’en servent au moment critique. Une CRL n’a rien de magique : ce sont des champs, des dates, une signature, et des clients plus ou moins stricts.
Ce qu’on trouve dedans : numéro de série, dates, raisons de révocation
Une CRL est signée par l’autorité qui l’émet (CA). Elle contient surtout une liste d’entrées correspondant aux certificats révoqués, identifiés par leur numéro de série (serial number). C’est important : on ne cherche pas par nom DNS mais par identifiant unique du certificat, celui qui permet d’éviter les ambiguïtés.
Vous y trouverez aussi thisUpdate et nextUpdate. ThisUpdate indique quand cette version a été publiée. NextUpdate indique jusqu’à quand elle est considérée comme valide avant rafraîchissement attendu. Quand nextUpdate est dépassé chez vos clients sans nouvelle liste récupérée, les erreurs du type « CRL expired » ne tardent pas.
Il y a enfin souvent une raison de révocation (reason code) associée à chaque entrée. Exemple fréquent : compromission présumée (« key compromise »), cessation d’activité (« cessation of operation »), remplacement (« superseded »). Ce champ aide en audit, mais ne change pas toujours le comportement technique du client lors de la validation TLS.
| Champ / notion | À quoi ça sert | Où on le voit | Risque si mal géré |
|---|---|---|---|
| Numéro de série | Identifier précisément un certificat | Entrées « certificat révoqué » | Révocations non prises en compte |
| thisUpdate | Date et heure de publication | En-tête CRL | Doute sur la fraîcheur |
| nextUpdate | Date et heure limite attendue | En-tête CRL | Erreurs « CRL expired » |
| Raison | Contexte audit et conformité | reasonCode | Mauvaise lecture d’incident |
| Signature CA | Garantit intégrité et authenticité | Selon outils, en-tête ou fin | Liste falsifiable si absence |
Vous vous demandez peut-être comment lire tout ça sans y passer l’après-midi. Dans les faits, on finit avec une vérification courte : dates cohérentes, signature valide, CA attendue, et URL stable côté clients. Le reste sert surtout à comprendre « pourquoi » après coup.
CRL complète vs Delta CRL : la bonne option selon votre volume
Une CRL complète contient toutes les entrées révoquées connues au moment T, tant qu’elles restent pertinentes selon la politique de la CA. Plus votre volumétrie grandit (beaucoup d’équipements certifiés), plus cette liste grossit et devient pénible à distribuer rapidement partout. Ce n’est pas qu’une question de taille : c’est aussi une question de temps de téléchargement, de cache et de fiabilité réseau.
La Delta CRL répond à ce problème : elle ne contient que les changements depuis la dernière base publiée (les nouvelles révocations). Les clients combinent alors « base + delta » pour reconstituer l’état courant, sans retélécharger la liste complète à chaque fois. Sur le papier, c’est élégant et efficace.
En pratique, c’est très utile dans des environnements Microsoft AD CS avec beaucoup d’émissions internes, ou dans certaines PKI industrielles où les objets sont nombreux. L’inconvénient tient en deux mots : compatibilité client et complexité opérationnelle. Si vos consommateurs ne gèrent pas bien les deltas, ou si votre supervision n’est pas mûre, rester sur une CRL complète publiée plus fréquemment peut être plus robuste au quotidien.
Astuce terrain : avant d’activer Delta CRL parce que « c’est plus moderne », posez-vous une question simple : qui va dépanner quand base et delta ne s’alignent plus après une restauration, une rotation de publication ou un incident réseau ? Ce scénario arrive, et il coûte cher en temps.
Pour mieux comprendre les enjeux de la gestion des certificats, notre article sur les frais de gestion peut fournir des informations utiles.
Distribution et disponibilité : CDP, URL, LDAP, cache et résilience
Une bonne politique de révocation ne vaut rien si personne ne peut récupérer la liste au bon moment. Sur le terrain, beaucoup d’incidents viennent moins de la cryptographie que de la distribution.
CRL Distribution Points (CDP) : où le client va chercher l’info
Les CDP (« CRL Distribution Points ») sont des informations incluses dans le certificat X.509 indiquant où télécharger la CRL associée à cette CA émettrice. En clair : c’est l’adresse officielle que le client va suivre pour récupérer la liste et vérifier le statut.
Les CDP pointent souvent vers une URL HTTP(S) ou vers LDAP (annuaire). HTTP(S) fonctionne bien côté clients variés car c’est simple à faire passer à travers réseau et proxy, à condition d’avoir ouvert les flux et stabilisé le nom. LDAP reste courant en environnements Windows internes parce qu’il colle aux usages Active Directory et aux habitudes d’administration.
Ce détail paraît administratif jusqu’au jour où vous changez un proxy sortant, segmentez un réseau serveur, ou durcissez des règles de filtrage sans penser aux flux vers ces CDP. Résultat immédiat côté applications strictes : « unable to get certificate CRL » pendant des connexions TLS qui marchaient depuis des mois. Et comme rien n’a changé « dans l’application », le diagnostic part souvent dans la mauvaise direction.
Petit aparté que je vois revenir souvent : beaucoup confondent CDP avec AIA (Authority Information Access). AIA sert plutôt à récupérer les certificats intermédiaires pour reconstruire la chaîne. CDP sert au statut via listes CRL, donc au contrôle de révocation.
Performance et fiabilité : cache, diffusion, multi-URL, supervision
Les clients utilisent généralement un cache CRL local pour éviter des téléchargements permanents. C’est une bonne nouvelle pour les performances, mais une mauvaise surprise quand vous voulez forcer une prise en compte rapide après incident. Certains postes peuvent garder l’ancien état jusqu’au prochain rafraîchissement prévu, ou jusqu’à une invalidation manuelle selon le système et les outils.
Pour améliorer la disponibilité réelle, on joue sur trois leviers très concrets. D’abord, publier via plusieurs points CDP (multi-URL) afin qu’un client ait un plan B. Ensuite, placer la distribution derrière une infrastructure robuste, par exemple un mécanisme de diffusion adapté à votre contexte. Enfin, superviser explicitement thisUpdate et nextUpdate depuis plusieurs zones réseau, pour détecter un problème avant qu’il devienne un incident visible.
La question qui tranche souvent est organisationnelle. Qui porte cette supervision ? L’équipe infrastructure pilote l’URL, mais c’est souvent la sécurité qui subit quand les contrôles échouent. Si personne n’a l’alerte, nextUpdate sera dépassé tranquillement, puis tout explosera au moment le moins pratique.
OCSP, OCSP stapling: quand préférer une vérification en temps réel
Les listes sont utiles, mais parfois trop lentes ou trop lourdes à distribuer. L’idée derrière OCSP est simple : demander « est-il révoqué ? » au moment où on vérifie, plutôt que de dépendre uniquement d’une liste téléchargée plus tôt.
CRL vs OCSP: avantages, limites et critères
Une CRL fonctionne par publication périodique. C’est robuste, simple à comprendre, et compatible avec beaucoup d’écosystèmes, mais cela introduit une notion de délai : entre une révocation et sa prise en compte effective par tous les clients, il peut se passer du temps. Ce décalage dépend du rythme de publication, du cache et des contraintes réseau.
OCSP, lui, repose sur une requête en ligne vers un répondeur qui répond sur le statut d’un certificat. L’intérêt est évident : on peut obtenir un statut plus frais, surtout si la CRL est volumineuse ou si vous voulez éviter des téléchargements réguliers. En contrepartie, vous introduisez une dépendance à un service temps réel, donc à sa disponibilité, sa latence et son exposition réseau.
OCSP stapling ajoute une variante pratique côté TLS : au lieu de laisser chaque client interroger le répondeur, c’est le serveur qui « agrafe » une preuve OCSP récente dans la poignée de main TLS. Le client vérifie alors cette preuve sans faire d’appel réseau supplémentaire. Cela améliore les performances et évite que des clients soient bloqués par un proxy ou un filtrage sortant.
Le choix entre CRL et OCSP n’est pas purement technique, il est aussi opérationnel. Si vos clients sont très hétérogènes, la CRL reste souvent le dénominateur commun. Si vous maîtrisez bien vos serveurs et que vous cherchez à réduire les appels sortants des clients, OCSP stapling devient très séduisant. Et si vous avez des exigences fortes sur la fraîcheur, OCSP peut être un meilleur outil, à condition d’en assumer la disponibilité.
En clair : CRL, c’est la stabilité et la simplicité. OCSP, c’est la fraîcheur et la réactivité. OCSP stapling, c’est souvent le meilleur compromis quand l’écosystème le supporte, parce qu’il déplace la complexité du poste client vers l’infrastructure serveur, là où vous pouvez superviser et corriger.
La vérification en temps réel est essentielle, tout comme l’analyse des processus d’entreprise, que vous pouvez explorer dans notre article sur la chaîne de valeur de Porter.
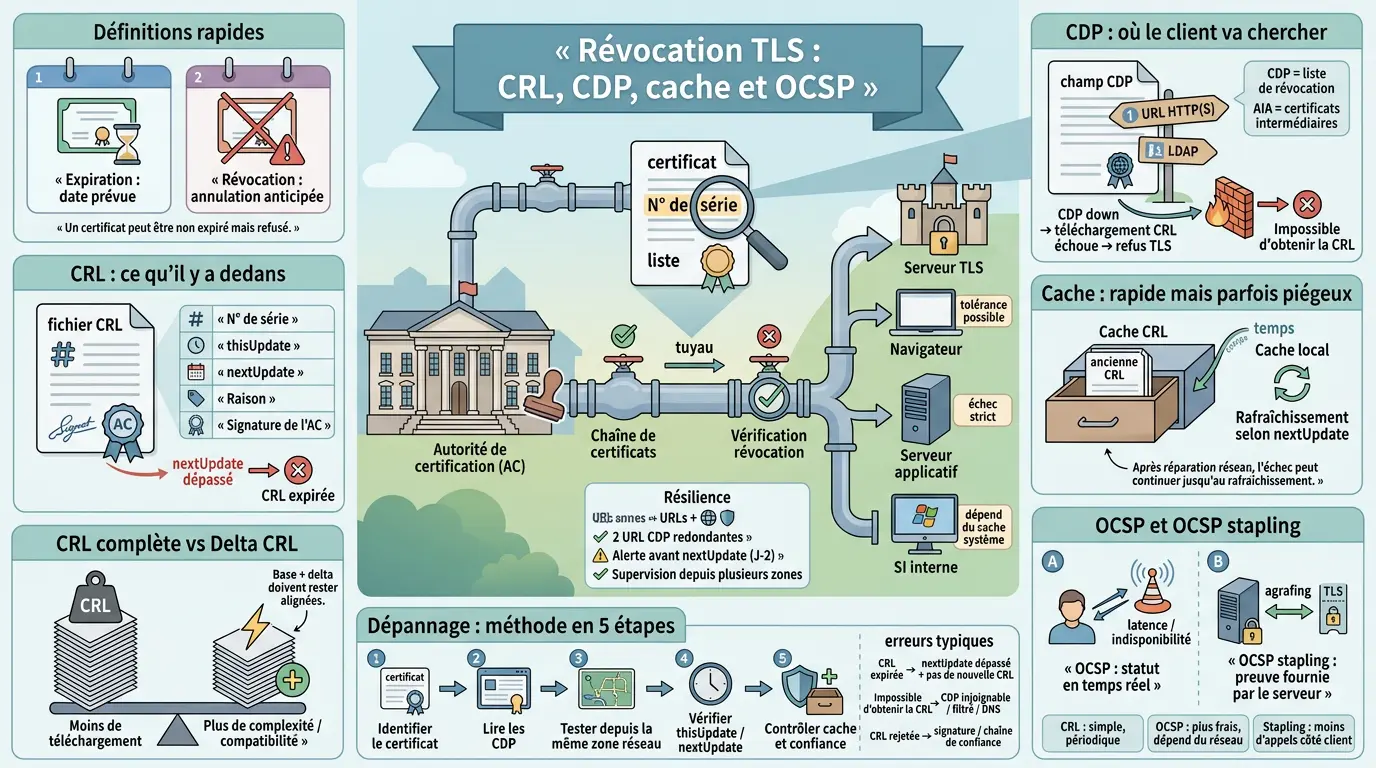
Dépannage : comprendre qui échoue, pourquoi, et comment corriger sans tâtonner
Quand une erreur de révocation apparaît, le piège classique est de « bricoler » côté application. Dans la majorité des cas, la panne est reproductible et explicable si vous remontez la chaîne : certificat, points de distribution, accès réseau, cache, puis politique de validation.
Les erreurs typiques et ce qu’elles racontent vraiment
« CRL expired » indique presque toujours un problème de fraîcheur : la liste en cache a dépassé nextUpdate, et le client n’a pas réussi à récupérer une version plus récente. La cause réelle peut être une publication qui n’a pas eu lieu, une distribution indisponible, ou un accès réseau cassé depuis une zone précise.
« Unable to get certificate CRL » pointe plutôt vers l’accès aux CDP : l’adresse est injoignable, filtrée, mal résolue, ou renvoie un contenu inattendu. Parfois, l’URL répond, mais avec une redirection ou un certificat serveur non reconnu, ce qui suffit à faire échouer certains clients.
Enfin, il existe des cas plus subtils : une CRL bien accessible, mais signée par une CA inattendue, ou une chaîne de confiance incomplète côté client. Dans ce scénario, la liste est téléchargée, mais rejetée comme non authentique. Là, l’erreur ressemble à un problème de révocation, alors que c’est un problème de confiance.
Une méthode simple pour isoler la cause
Commencez par identifier quel certificat déclenche la vérification : le certificat serveur, mais aussi parfois un intermédiaire selon les bibliothèques. Ensuite, regardez les CDP présents dans le certificat et testez leur accessibilité depuis la même zone réseau que le client en échec, pas depuis votre poste d’administration.
Vérifiez ensuite la cohérence des dates : thisUpdate et nextUpdate doivent correspondre à votre politique de publication. Une nextUpdate trop courte multiplie les incidents en cas de micro-coupure. Une nextUpdate trop longue réduit l’intérêt de la révocation en cas d’incident réel. Il faut un équilibre, et il doit être assumé.
Enfin, regardez le cache. Un poste peut conserver une CRL ancienne, même si la distribution est réparée, et continuer à échouer jusqu’au prochain rafraîchissement. C’est frustrant, mais c’est normal : le cache protège la performance et la stabilité, au prix d’une inertie.
Corriger durablement : ce qui évite les rechutes
La correction durable passe rarement par un « redémarrage du service » uniquement. Il faut sécuriser la publication, la distribution et la supervision. Une CRL doit être publiée à un rythme cohérent, accessible depuis toutes les zones qui valident, et surveillée comme un service critique.
Si vous n’avez qu’une seule URL de distribution, vous avez un point de défaillance unique. Si cette URL dépend d’un serveur peu supervisé, vous aurez des incidents récurrents. Et si personne ne surveille nextUpdate, vous découvrirez le problème au moment où les clients commenceront à refuser.
L’objectif n’est pas de rendre la PKI « parfaite », mais de la rendre prévisible. Une révocation est déjà un événement stressant ; la mécanique de contrôle ne doit pas ajouter du chaos. Quand la distribution est redondante et surveillée, la révocation redevient un outil de sécurité, pas une source de pannes incompréhensibles.
Foire aux questions
Qu’est-ce qu’une CRL et quel rôle joue-t-elle dans la sécurité TLS ?
Une CRL, ou liste de révocation de certificats, recense les certificats invalidés avant leur expiration par l’autorité de certification. Elle permet aux clients TLS de vérifier si un certificat est révoqué, évitant ainsi d’accepter des certificats compromis ou non autorisés, ce qui renforce la sécurité des connexions.
Pourquoi une erreur « CRL expired » peut-elle bloquer une connexion TLS ?
Cette erreur survient lorsque la liste de révocation en cache a dépassé sa date de validité (nextUpdate) et que le client n’a pas pu récupérer une version à jour. Sans liste fraîche, certains clients refusent la connexion par précaution, même si le certificat semble valide.
Comment les points de distribution CRL (CDP) influencent-ils la disponibilité des vérifications ?
Les CDP indiquent où les clients doivent télécharger la CRL. Si ces URL sont inaccessibles à cause d’un proxy, d’un filtrage réseau ou d’un serveur indisponible, la vérification échoue, provoquant souvent des refus de connexion TLS. Multiplier les points de distribution améliore la résilience.
Quelle différence y a-t-il entre CRL complète et Delta CRL ?
La CRL complète contient tous les certificats révoqués connus, tandis que la Delta CRL ne liste que les changements récents depuis la dernière publication complète. Le delta réduit la taille des transferts mais peut compliquer la gestion et la compatibilité client, surtout en cas d’incident.
Quand privilégier OCSP plutôt que la CRL pour vérifier la révocation ?
OCSP interroge en temps réel un serveur pour connaître le statut d’un certificat, offrant une fraîcheur immédiate. Ce mécanisme est préférable quand la rapidité et la précision sont cruciales, mais il dépend de la disponibilité du service, contrairement à la CRL qui reste un système plus simple et autonome.